
🎯 À quoi ça sert ?
- Restez à jour : Si vous changez un prix sur votre site web, le crawler le détectera lors de sa prochaine exécution.
- Base de connaissances massive : Idéal si vous avez des centaines d’articles d’aide ou de pages produits.
- Vérification : Permet à l’agent de citer des sources réelles (« D’après notre site web… »).
🛠️ Configurer un Crawler (Étape par étape)
Lorsque vous cliquez sur + Ajouter un Web Crawler, vous verrez l’écran de configuration. Considérez-le comme la carte de mission de votre crawler.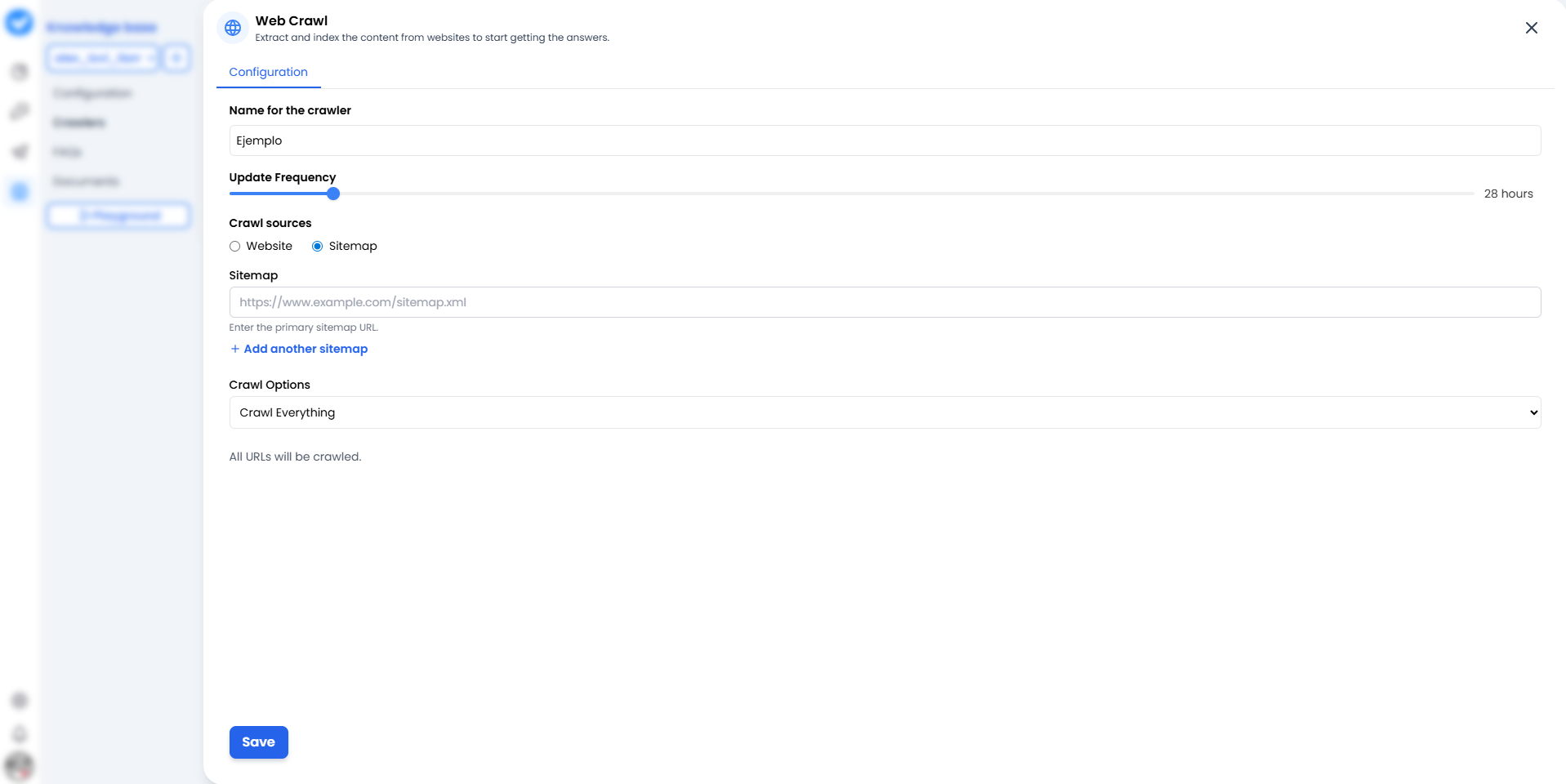
1. Nom du crawler
Donnez-lui un nom qui identifie clairement la source.- Mauvais : « Test 1 ».
- Bon :
Support_Officiel_AideouBlog_Mises_a_jour_2024.
2. Fréquence de mise à jour (Le rythme)
À quelle fréquence doit-il relire le site web ? Utilisez le curseur.- 24 heures : L’option standard. Vérifie les changements une fois par jour.
- Plus fréquent : À utiliser uniquement pour les actualités urgentes (consomme plus de ressources).
3. Sources de crawl (La stratégie)
Ici vous décidez comment le bot entre chez vous :- 🌐 Site web : Le bot commence par la page d’accueil et suit les liens un par un (comme un humain curieux). Bon pour découvrir du contenu.
- 🗺️ Sitemaps (Nouveau et amélioré !) : Vous lui donnez une carte exacte (
sitemap.xml). Le meilleur ? Vous n’êtes plus limité à un seul. Vous pouvez cliquer sur + Ajouter un autre sitemap pour donner au bot plusieurs cartes à la fois. Vous pouvez aussi utiliser le bouton Vérifier les sitemaps pour vérifier qu’ils fonctionnent correctement avant de lancer. Plus rapide, plus propre et bien plus efficace.
4. Options de crawl (La portée)
- Tout crawler : Il lira tout ce qu’il trouve.
- Sous-chemins : Vous pouvez le restreindre à
/blogou/produitspour qu’il ne perde pas de temps sur la page « À propos ».
⚠️ Important : Assurez-vous que votre site web ne bloque pas les bots (vérifiez votre robots.txt). Si vous fermez la porte, il ne pourra pas apprendre !
📄 Gérer vos connaissances (L’onglet « Pages »)
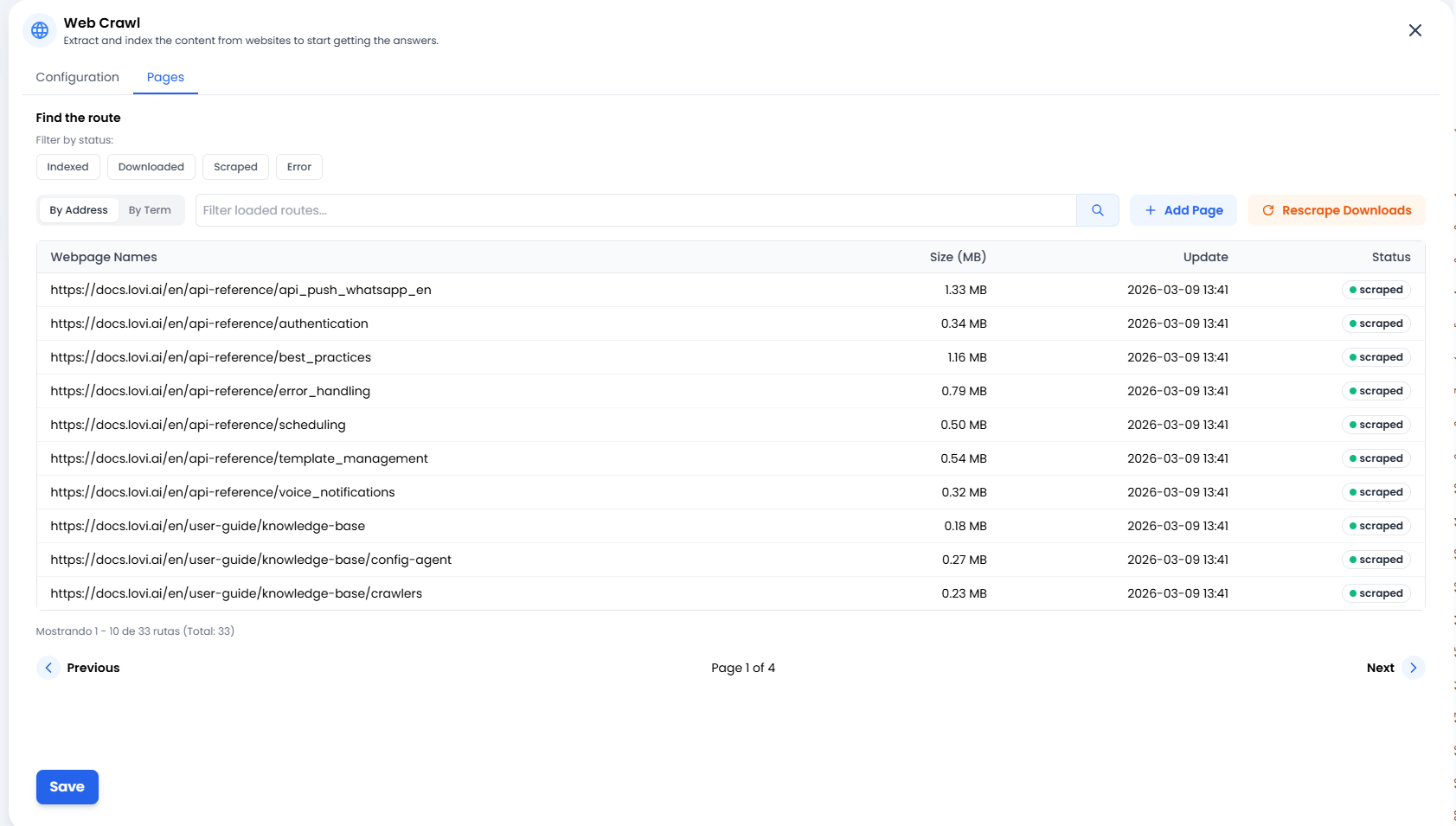
➕ Ajouter une page (Précision chirurgicale)
Parfois vous n’avez pas besoin de crawler un site entier ou un sitemap complet. Si vous venez de publier un nouvel article de blog ou un article externe que vous voulez que le bot apprenne tout de suite, cliquez simplement sur + Ajouter une page. Cela vous permet d’injecter manuellement des URL spécifiques directement dans le cerveau du bot.🔄 Re-scraper les téléchargements (La seconde chance)
Une connexion au site web a-t-elle planté ? Ou peut-être avez-vous mis à jour le texte de votre site et voulez que le bot l’apprenne immédiatement sans attendre le prochain cycle programmé ? Cliquez sur le bouton Re-scraper les téléchargements. Cela dit au système : « Reprends tous les documents déjà téléchargés et essaie d’extraire leurs informations à nouveau. » C’est le bouton de rafraîchissement parfait.📊 Feux de signalisation de statut (Que se passe-t-il ?)
Dans la liste des pages, vous verrez le statut exact de chaque URL. Voici ce qu’ils signifient :- 🟢 Scrapé / Indexé : Succès ! ✅ Le contenu a été lu, traité et est maintenant stocké en toute sécurité dans le cerveau de l’agent.
- 🟠 Téléchargé : La page a été téléchargée mais pas encore traitée (elle est encore en train de « digérer » l’information).
- 🔴 Erreur : Quelque chose s’est mal passé. Le site web est peut-être en panne, nécessite une connexion ou a un pare-feu anti-bot qui bloque l’accès.
🎓 Résumé des bonnes pratiques (Aide-mémoire)
Pour maintenir une bibliothèque de connaissances propre et utile :- Les sitemaps multiples sont vos meilleurs amis : Au lieu de crawler un site web massif, fournissez des sitemaps spécifiques (ex.
sitemap-produits.xmletsitemap-blog.xml). Cela garde le bot concentré. - Évitez les pages inutiles : Vous n’avez pas besoin d’indexer « Panier », « Connexion » ou « Mentions légales ».
- Nommage clair : Quand vous aurez 10 crawlers, vous serez content de les avoir nommés
FAQ_FRetFAQ_ENau lieu deweb1etweb2. - Ajouts chirurgicaux : Utilisez le bouton + Ajouter une page pour des mises à jour rapides au lieu de forcer un crawl complet de votre site.
🆘 Dépannage rapide
| Problème | Solution probable 🔧 |
|---|---|
| Le statut indique « Erreur » 🔴 | Votre site web bloque peut-être les bots. Vérifiez les paramètres de votre pare-feu. Si c’était un problème temporaire, essayez de cliquer sur Re-scraper les téléchargements. |
| Lit trop de pages | Passez à l’option Sitemap ou restreignez les sous-chemins pour qu’il ne lise que ce qui compte. |
| Les informations ne se mettent pas à jour | Vérifiez le curseur « Fréquence de mise à jour ». Il est peut-être réglé sur « Mensuel » alors que vous avez besoin de « Quotidien ». |
| L’agent mélange les données | Avez-vous deux crawlers qui lisent le même contenu ? Supprimez les doublons. |