
🎯 这有什么用?
- 保持最新: 如果您更改了网站上的价格,爬虫将在下次运行时检测到。
- 大型知识库: 如果您有数百篇帮助文章或产品页面,这是理想选择。
- 验证: 允许智能体引用真实来源(“根据我们的网站……”)。
🛠️ 配置爬虫(分步指南)
当您点击 + 添加 Web 爬虫时,您将看到配置界面。可以将其视为爬虫的任务地图。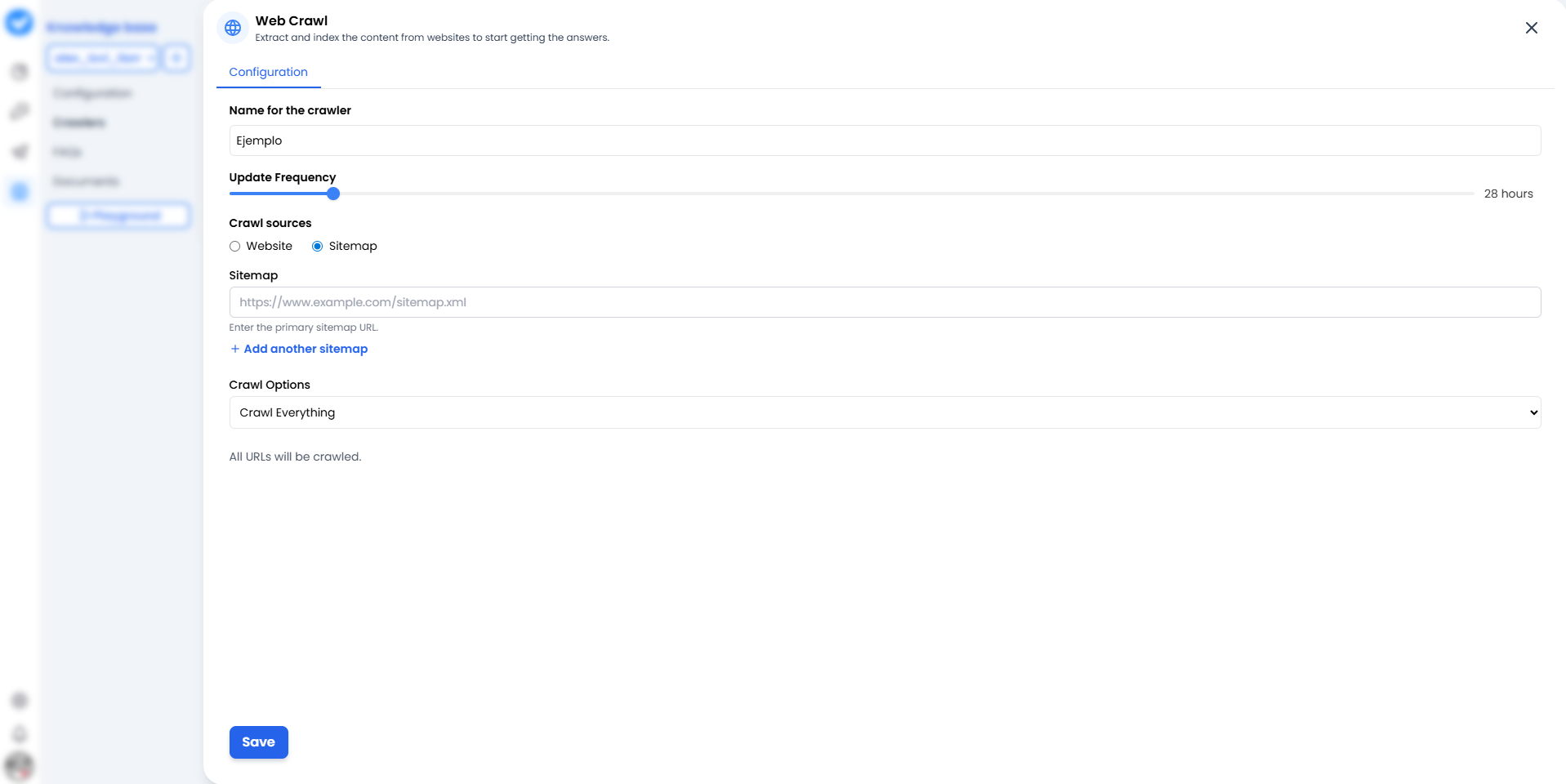
1. 爬虫名称
给它一个能清楚标识来源的名称。- 不好的: “测试 1”。
- 好的:
Official_Support_Help或Blog_Updates_2024。
2. 更新频率(节奏)
它应该多频繁地重新阅读网站?使用滑块。- 24 小时: 标准选项。每天检查一次变更。
- 更频繁: 仅用于突发新闻(消耗更多资源)。
3. 抓取来源(策略)
在这里决定机器人如何进入您的网站:- 🌐 网站: 机器人从主页开始,一个接一个地跟踪链接(像好奇的人类一样)。适合发现内容。
- 🗺️ 站点地图(全新改进!): 您给它一个精确的地图(
sitemap.xml)。最棒的是?您不再限于仅一个。 您可以点击 + 添加另一个站点地图来同时提供多个地图。您还可以使用检查站点地图按钮在启动前验证它们是否正常工作。更快、更干净、效率更高。
4. 抓取选项(范围)
- 抓取所有: 它将阅读找到的所有内容。
- 子路径: 您可以将其限制在
/blog或/products,这样它就不会浪费时间在”关于我们”页面上。
⚠️ 重要提示: 确保您的网站没有阻止机器人(检查您的 robots.txt)。如果您关上门,它就无法学习!
📄 管理您的知识(“页面”标签页)
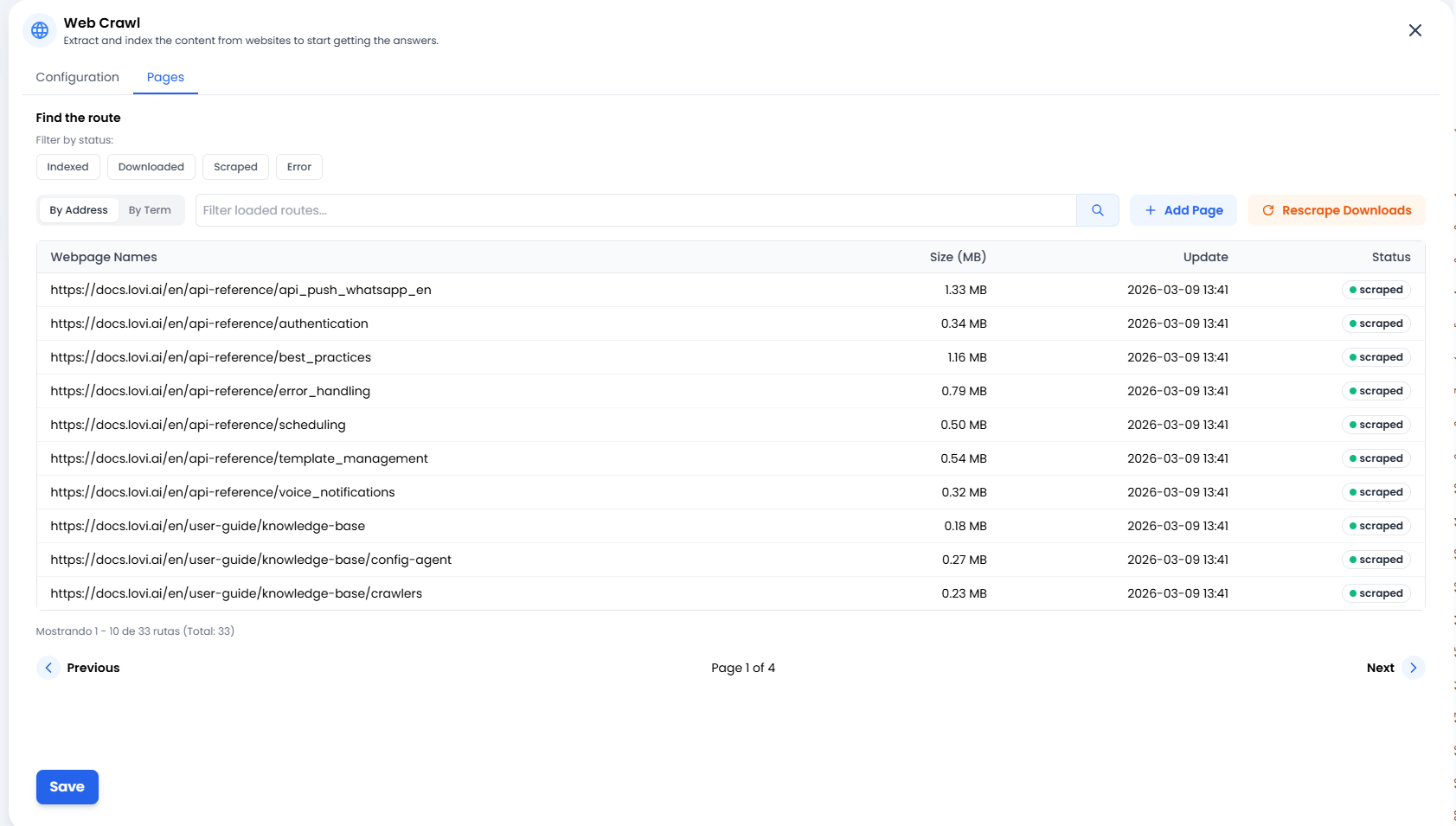
➕ 添加页面(精准操作)
有时您不需要抓取整个网站或整个站点地图。如果您刚刚发布了一篇新博客文章或想让机器人立即学习的外部文章,只需点击 + 添加页面。这允许您手动将特定 URL 直接注入机器人的大脑。🔄 重新抓取下载内容(第二次机会)
网站连接出现了问题?或者您更新了网站上的文字,想让机器人立即学习而不等待下一个计划周期? 点击重新抓取下载内容按钮。这告诉系统:“把我们已经下载的所有文档重新提取信息。” 这是完美的刷新按钮。📊 状态信号灯(发生了什么?)
在页面列表中,您将看到每个 URL 的确切状态。以下是它们的含义:- 🟢 已抓取 / 已索引: 成功!✅ 内容已被读取、处理并安全存储在智能体的大脑中。
- 🟠 已下载: 页面已下载但尚未处理(它仍在”消化”信息)。
- 🔴 错误: 出了问题。网站可能已关闭、需要登录或有防机器人防火墙阻止。
🎓 最佳实践总结(备忘单)
保持干净有用的知识库:- 多个站点地图是您最好的朋友: 与其抓取一个大型网站,不如提供特定的站点地图(如
sitemap-products.xml和sitemap-blog.xml)。这让机器人保持专注。 - 避免垃圾页面: 您不需要索引”购物车”、“登录”或”法律声明”。
- 清晰命名: 当您有 10 个爬虫时,您会庆幸自己将它们命名为
FAQ_ES和FAQ_EN,而不是web1和web2。 - 精准添加: 使用 + 添加页面按钮进行快速更新,而不是强制全站抓取。
🆘 快速故障排除
| 问题 | 可能的解决方法 🔧 |
|---|---|
| 状态显示”错误” 🔴 | 您的网站可能阻止了机器人。检查防火墙设置。如果是临时问题,尝试点击重新抓取下载内容。 |
| 读取了太多页面 | 切换到站点地图选项或限制子路径,让它只读取重要内容。 |
| 信息未更新 | 检查”更新频率”滑块。可能设置为”每月”而您需要”每天”。 |
| 智能体混淆数据 | 您有两个爬虫在读取相同的内容吗?删除重复项。 |