
🎯 Para que serve?
- Mantenha atualizado: Se você mudar um preço no seu site, o crawler detectará na próxima execução.
- Base de conhecimento enorme: Ideal se você tem centenas de artigos de ajuda ou páginas de produtos.
- Verificação: Permite que o agente cite fontes reais (“De acordo com nosso site…”).
🛠️ Configurando um Crawler (Passo a Passo)
Quando você clica em + Adicionar Web Crawler, verá a tela de configuração. Pense nisso como o mapa da missão para seu crawler.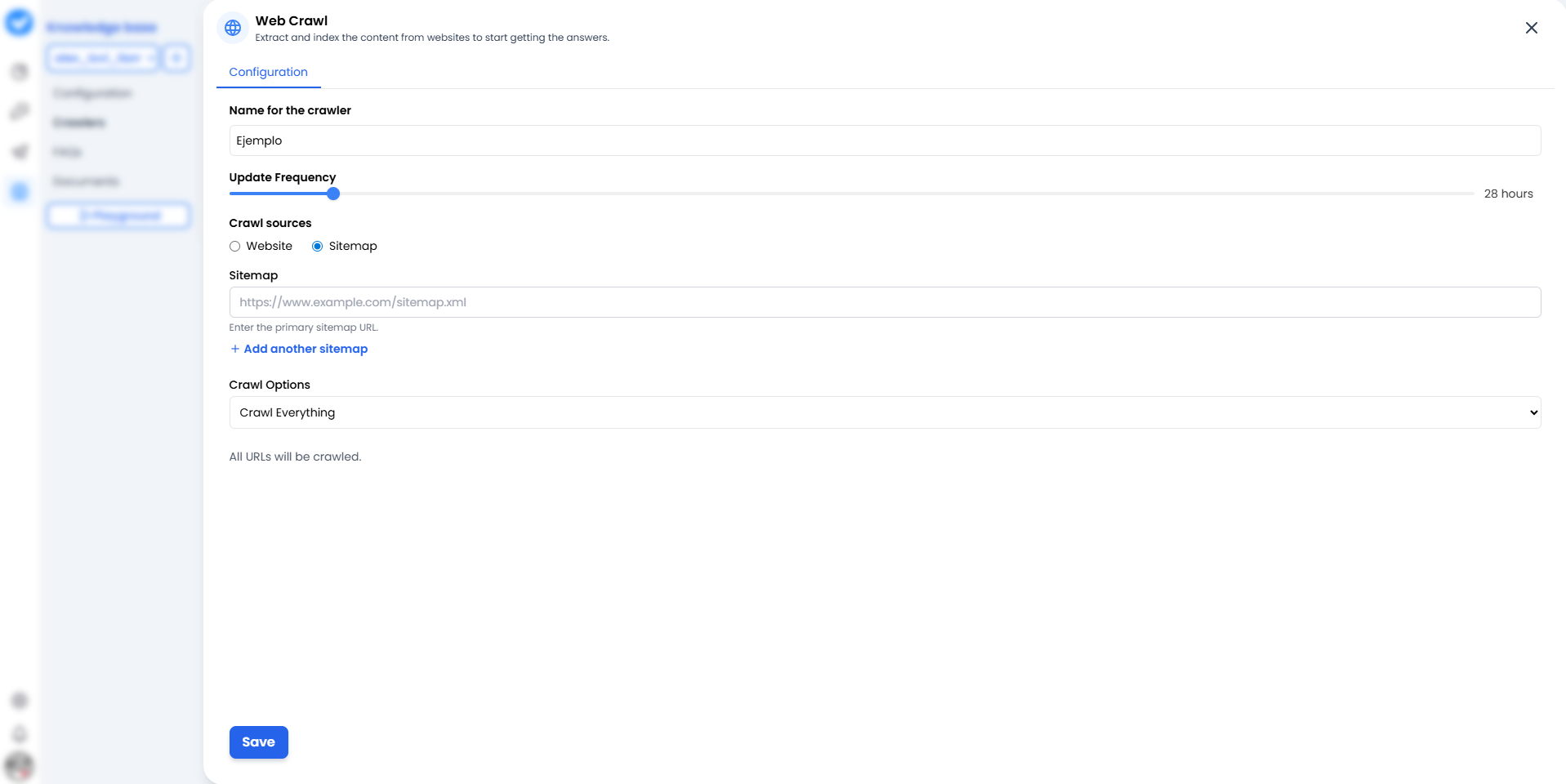
1. Nome para o crawler
Dê um nome que identifique claramente a fonte.- Ruim: “Teste 1”.
- Bom:
Suporte_Oficial_AjudaouBlog_Atualizacoes_2024.
2. Frequência de Atualização (O Ritmo)
Com que frequência ele deve reler o site? Use o controle deslizante.- 24 horas: A opção padrão. Verifica mudanças uma vez por dia.
- Mais frequente: Use apenas para notícias de última hora (consome mais recursos).
3. Fontes de Crawl (A Estratégia)
Aqui você decide como o bot entra na sua casa:- 🌐 Website: O bot começa pela página inicial e segue links um por um (como um humano curioso). Bom para descobrir conteúdo.
- 🗺️ Sitemaps (Novo e Melhorado!): Você dá a ele um mapa exato (
sitemap.xml). A melhor parte? Você não está mais limitado a apenas um. Você pode clicar em + Adicionar outro sitemap para alimentar o bot com múltiplos mapas de uma vez. Você também pode usar o botão Verificar Sitemaps para confirmar que estão funcionando corretamente antes de lançar. Mais rápido, mais limpo e muito mais eficiente.
4. Opções de Crawl (O Escopo)
- Rastrear Tudo: Ele lerá tudo que encontrar.
- Sub-caminhos: Você pode restringir a
/blogou/produtospara que não perca tempo na página “Sobre nós”.
⚠️ Importante: Certifique-se de que seu site não bloqueia bots (verifique seu robots.txt). Se você fechar a porta, ele não poderá aprender!
📄 Gerenciando seu Conhecimento (A Aba “Páginas”)
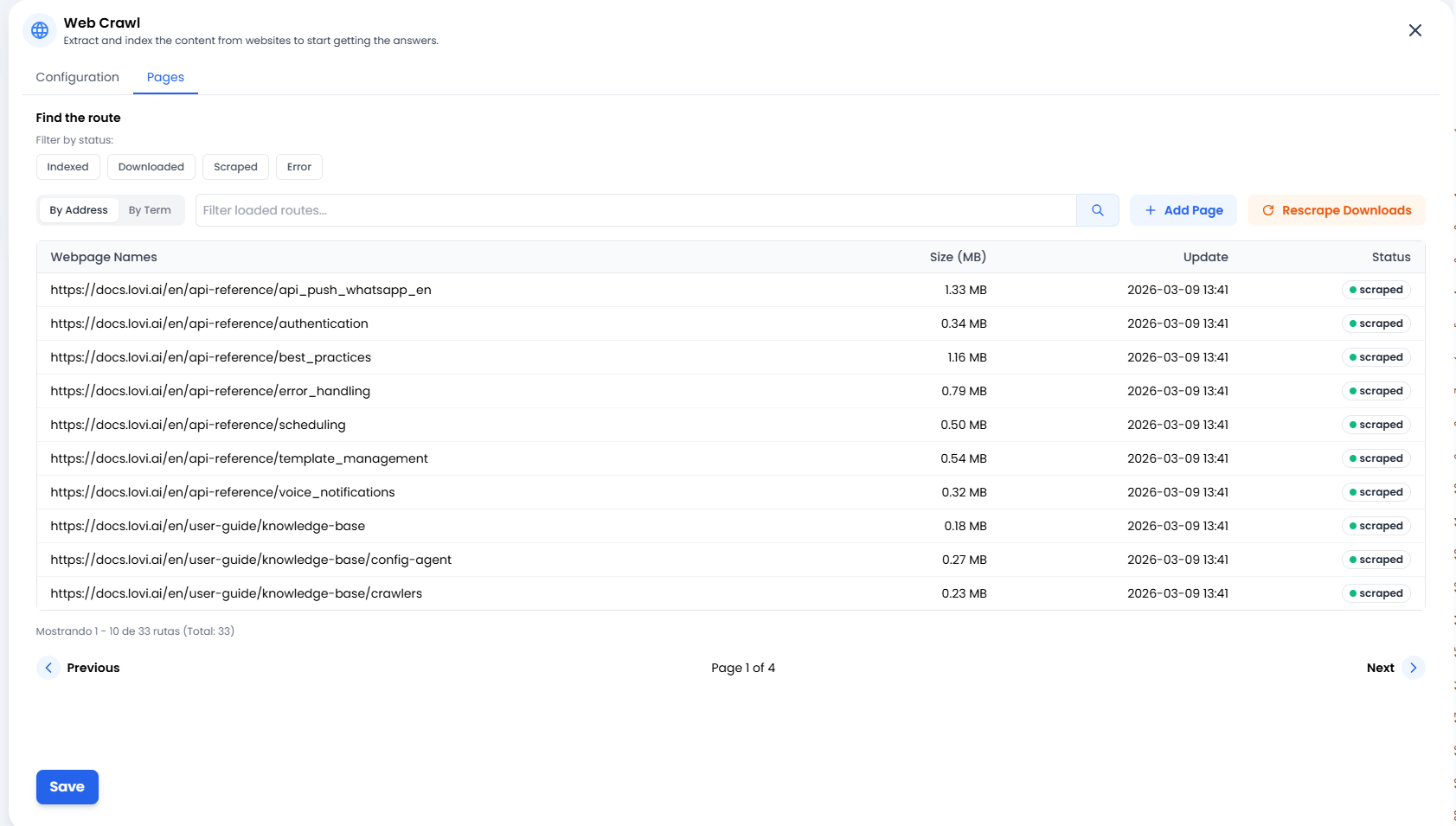
➕ Adicionar Página (Precisão Cirúrgica)
Às vezes você não precisa rastrear um site inteiro ou um sitemap completo. Se você acabou de publicar um novo post no blog ou um artigo externo que quer que o bot aprenda agora, simplesmente clique em + Adicionar Página. Isso permite que você injete manualmente URLs específicas diretamente no cérebro do bot.🔄 Re-rastrear Downloads (A Segunda Chance)
A conexão com um site deu problema? Ou talvez você tenha atualizado o texto no seu site e quer que o bot aprenda imediatamente sem esperar o próximo ciclo agendado? Clique no botão Re-rastrear Downloads. Isso diz ao sistema: “Pegue todos os documentos que já baixamos e tente extrair suas informações novamente.” É o botão de atualização perfeito.📊 Semáforos de Status (O que está acontecendo?)
Na lista de Páginas, você verá o status exato de cada URL. Aqui está o que significam:- 🟢 Rastreado / Indexado: Sucesso! ✅ O conteúdo foi lido, processado e agora está armazenado com segurança no cérebro do agente.
- 🟠 Baixado: A página foi baixada mas ainda não processada (ainda está “digerindo” a informação).
- 🔴 Erro: Algo deu errado. O site pode estar fora do ar, exigir login ou ter um firewall anti-bot bloqueando o caminho.
🎓 Resumo de Boas Práticas (Cola Rápida)
Para manter uma biblioteca de conhecimento limpa e útil:- Múltiplos Sitemaps são seu melhor amigo: Em vez de rastrear um site enorme, forneça sitemaps específicos (ex.:
sitemap-produtos.xmlesitemap-blog.xml). Mantém o bot focado. - Evite páginas inúteis: Você não precisa indexar “Carrinho de Compras”, “Login” ou “Aviso Legal”.
- Nomes claros: Quando você tiver 10 crawlers, ficará feliz por tê-los nomeado
FAQ_PTeFAQ_ENem vez deweb1eweb2. - Adições cirúrgicas: Use o botão + Adicionar Página para atualizações rápidas em vez de forçar um rastreamento completo do seu site.
🆘 Solução Rápida de Problemas
| Problema | Provável Solução 🔧 |
|---|---|
| Status diz “Erro” 🔴 | Seu site pode estar bloqueando bots. Verifique as configurações do firewall. Se foi uma falha temporária, tente clicar em Re-rastrear Downloads. |
| Lê páginas demais | Mude para a opção Sitemap ou restrinja os Sub-caminhos para que leia apenas o que importa. |
| Informação não atualiza | Verifique o controle deslizante “Frequência de Atualização”. Pode estar definido como “Mensal” quando você precisa de “Diário”. |
| O agente mistura dados | Você tem dois crawlers lendo o mesmo conteúdo? Remova duplicatas. |