
🎯 Wofür ist das da?
- Immer aktuell: Wenn Sie einen Preis auf Ihrer Website ändern, erkennt der Crawler dies beim nächsten Durchlauf.
- Riesige Wissensdatenbank: Ideal, wenn Sie Hunderte von Hilfeartikeln oder Produktseiten haben.
- Verifizierung: Ermöglicht dem Agenten, echte Quellen zu zitieren (“Laut unserer Website…”).
🛠️ Einen Crawler konfigurieren (Schritt für Schritt)
Wenn Sie auf + Web Crawler hinzufügen klicken, sehen Sie den Konfigurationsbildschirm. Betrachten Sie es als die Missionskarte für Ihren Crawler.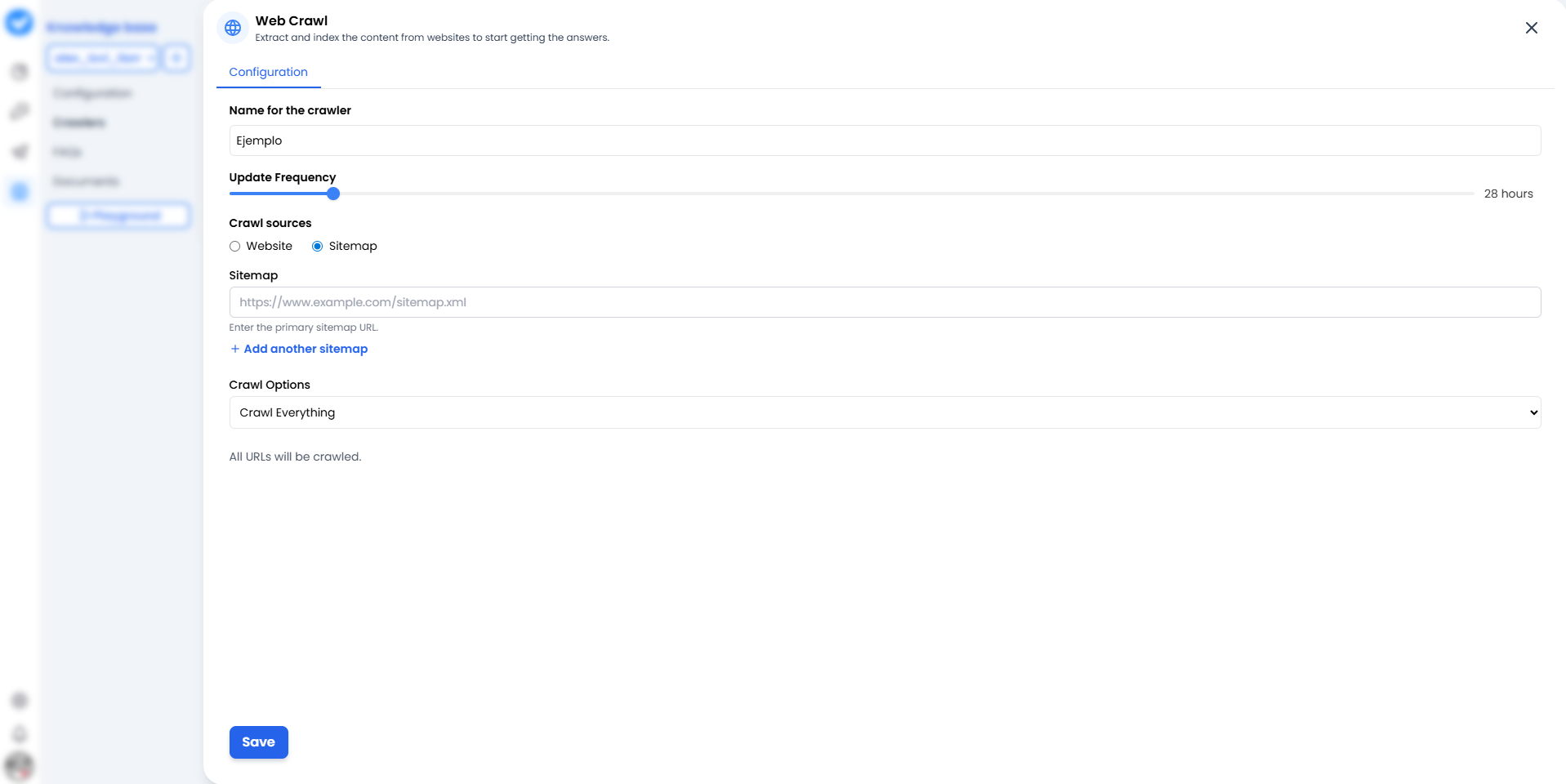
1. Name für den Crawler
Geben Sie ihm einen Namen, der die Quelle klar identifiziert.- Schlecht: “Test 1”.
- Gut:
Offizieller_Support_HilfeoderBlog_Updates_2024.
2. Aktualisierungshäufigkeit (Der Rhythmus)
Wie oft soll er die Website erneut lesen? Verwenden Sie den Schieberegler.- 24 Stunden: Die Standardoption. Prüft einmal täglich auf Änderungen.
- Häufiger: Verwenden Sie dies nur für aktuelle Nachrichten (verbraucht mehr Ressourcen).
3. Crawl-Quellen (Die Strategie)
Hier entscheiden Sie, wie der Bot Ihr Haus betritt:- 🌐 Website: Der Bot beginnt auf der Startseite und folgt Links einzeln (wie ein neugieriger Mensch). Gut zum Entdecken von Inhalten.
- 🗺️ Sitemaps (Neu & Verbessert!): Sie geben ihm eine genaue Karte (
sitemap.xml). Das Beste daran? Sie sind nicht mehr auf nur eine beschränkt. Sie können auf + Weitere Sitemap hinzufügen klicken, um dem Bot mehrere Karten gleichzeitig zu geben. Sie können auch die Schaltfläche Sitemaps prüfen verwenden, um zu überprüfen, ob sie ordnungsgemäß funktionieren, bevor Sie starten. Schneller, sauberer und viel effizienter.
4. Crawl-Optionen (Der Umfang)
- Alles crawlen: Er liest alles, was er findet.
- Unterpfade: Sie können ihn auf
/blogoder/produktebeschränken, damit er keine Zeit mit der “Über uns”-Seite verschwendet.
⚠️ Wichtig: Stellen Sie sicher, dass Ihre Website Bots nicht blockiert (prüfen Sie Ihre robots.txt). Wenn Sie die Tür schließen, kann er nicht lernen!
📄 Ihr Wissen verwalten (Der “Seiten”-Tab)
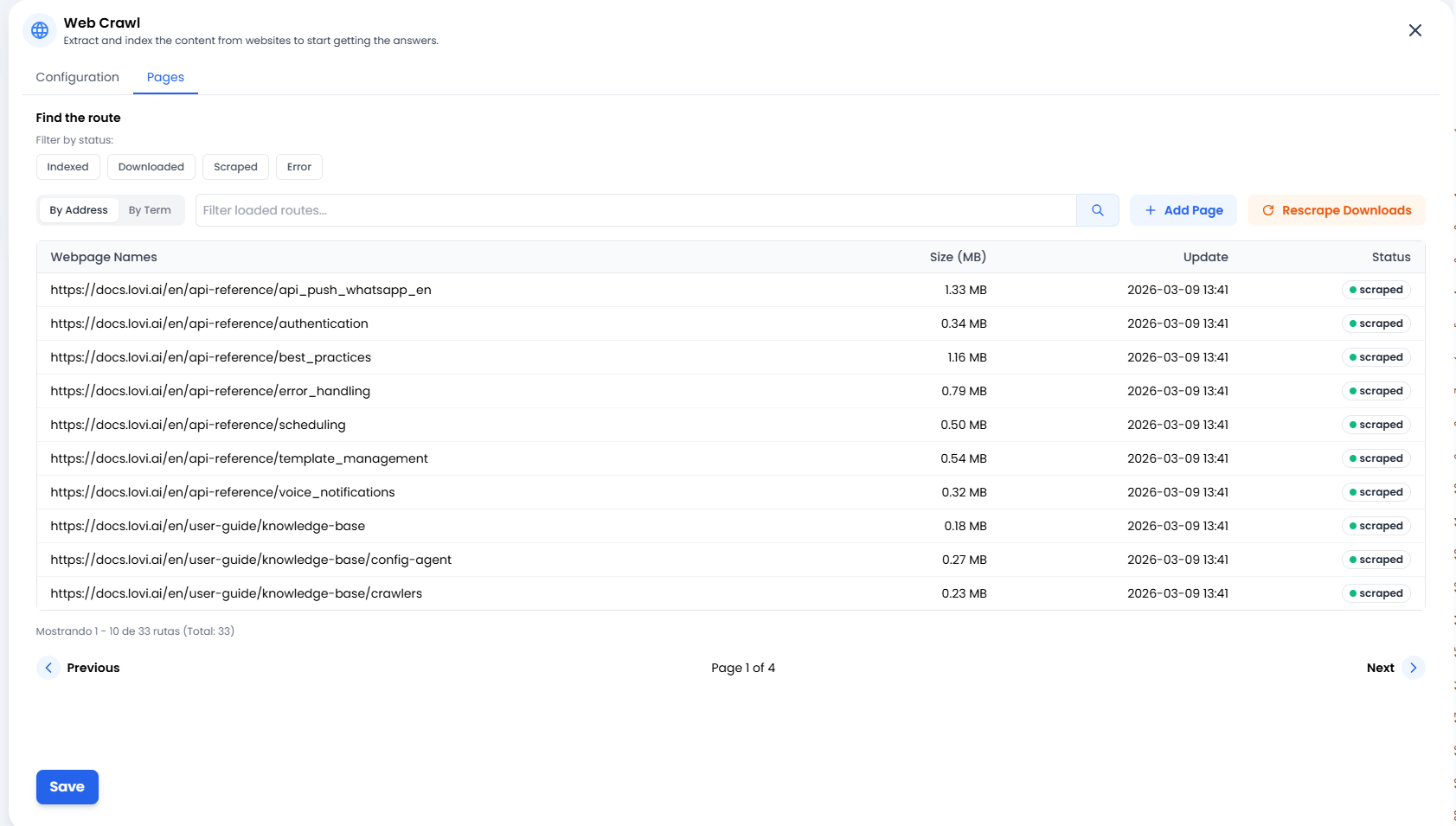
➕ Seite hinzufügen (Chirurgische Präzision)
Manchmal müssen Sie nicht eine ganze Website oder eine komplette Sitemap crawlen. Wenn Sie gerade einen einzelnen neuen Blogbeitrag oder einen externen Artikel veröffentlicht haben, den der Bot sofort lernen soll, klicken Sie einfach auf + Seite hinzufügen. Dies ermöglicht es Ihnen, bestimmte URLs manuell direkt in das Gehirn des Bots einzuspeisen.🔄 Downloads neu scrapen (Die zweite Chance)
Hat eine Website-Verbindung nicht funktioniert? Oder haben Sie den Text auf Ihrer Website aktualisiert und möchten, dass der Bot ihn sofort lernt, ohne auf den nächsten geplanten Zyklus zu warten? Klicken Sie auf die Schaltfläche Downloads neu scrapen. Dies sagt dem System: “Nimm alle Dokumente, die wir bereits heruntergeladen haben, und versuche erneut, ihre Informationen zu extrahieren.” Es ist die perfekte Aktualisierungsschaltfläche.📊 Status-Ampeln (Was passiert?)
In der Seitenliste sehen Sie den genauen Status jeder einzelnen URL. Hier ist, was sie bedeuten:- 🟢 Gescrapt / Indexiert: Erfolg! ✅ Der Inhalt wurde gelesen, verarbeitet und ist nun sicher im Gehirn des Agenten gespeichert.
- 🟠 Heruntergeladen: Die Seite wurde heruntergeladen, aber noch nicht verarbeitet (sie “verdaut” die Informationen noch).
- 🔴 Fehler: Etwas ist schiefgelaufen. Die Website könnte down sein, einen Login erfordern oder eine Anti-Bot-Firewall hat den Weg blockiert.
🎓 Zusammenfassung der Best Practices (Spickzettel)
Um eine saubere und nützliche Wissensbibliothek zu pflegen:- Mehrere Sitemaps sind Ihr bester Freund: Anstatt eine riesige Website zu crawlen, stellen Sie spezifische Sitemaps bereit (z. B.
sitemap-produkte.xmlundsitemap-blog.xml). Das hält den Bot fokussiert. - Müllseiten vermeiden: Sie müssen “Warenkorb”, “Login” oder “Impressum” nicht indexieren.
- Klare Benennung: Wenn Sie 10 Crawler haben, werden Sie froh sein, sie
FAQ_DEundFAQ_ENstattweb1undweb2genannt zu haben. - Chirurgische Ergänzungen: Verwenden Sie die Schaltfläche + Seite hinzufügen für schnelle Updates, anstatt einen vollständigen Crawl Ihrer Website zu erzwingen.
🆘 Schnelle Fehlerbehebung
| Problem | Wahrscheinliche Lösung 🔧 |
|---|---|
| Status zeigt “Fehler” 🔴 | Ihre Website blockiert möglicherweise Bots. Prüfen Sie Ihre Firewall-Einstellungen. Wenn es ein vorübergehender Fehler war, versuchen Sie Downloads neu scrapen. |
| Liest zu viele Seiten | Wechseln Sie zur Sitemap-Option oder beschränken Sie die Unterpfade, damit nur gelesen wird, was zählt. |
| Informationen werden nicht aktualisiert | Prüfen Sie den Schieberegler “Aktualisierungshäufigkeit”. Er könnte auf “Monatlich” stehen, wenn Sie “Täglich” brauchen. |
| Der Agent vermischt Daten | Haben Sie zwei Crawler, die denselben Inhalt lesen? Entfernen Sie Duplikate. |