
🎯 A cosa serve?
- Mantienilo aggiornato: Se cambi un prezzo sul tuo sito web, il crawler lo rileverà alla prossima esecuzione.
- Base di conoscenza enorme: Ideale se hai centinaia di articoli di aiuto o pagine di prodotti.
- Verifica: Permette all’agente di citare fonti reali (“Secondo il nostro sito web…”).
🛠️ Configurare un Crawler (Passo dopo passo)
Quando clicchi + Aggiungi Web Crawler, vedrai la schermata di configurazione. Pensala come la mappa della missione per il tuo crawler.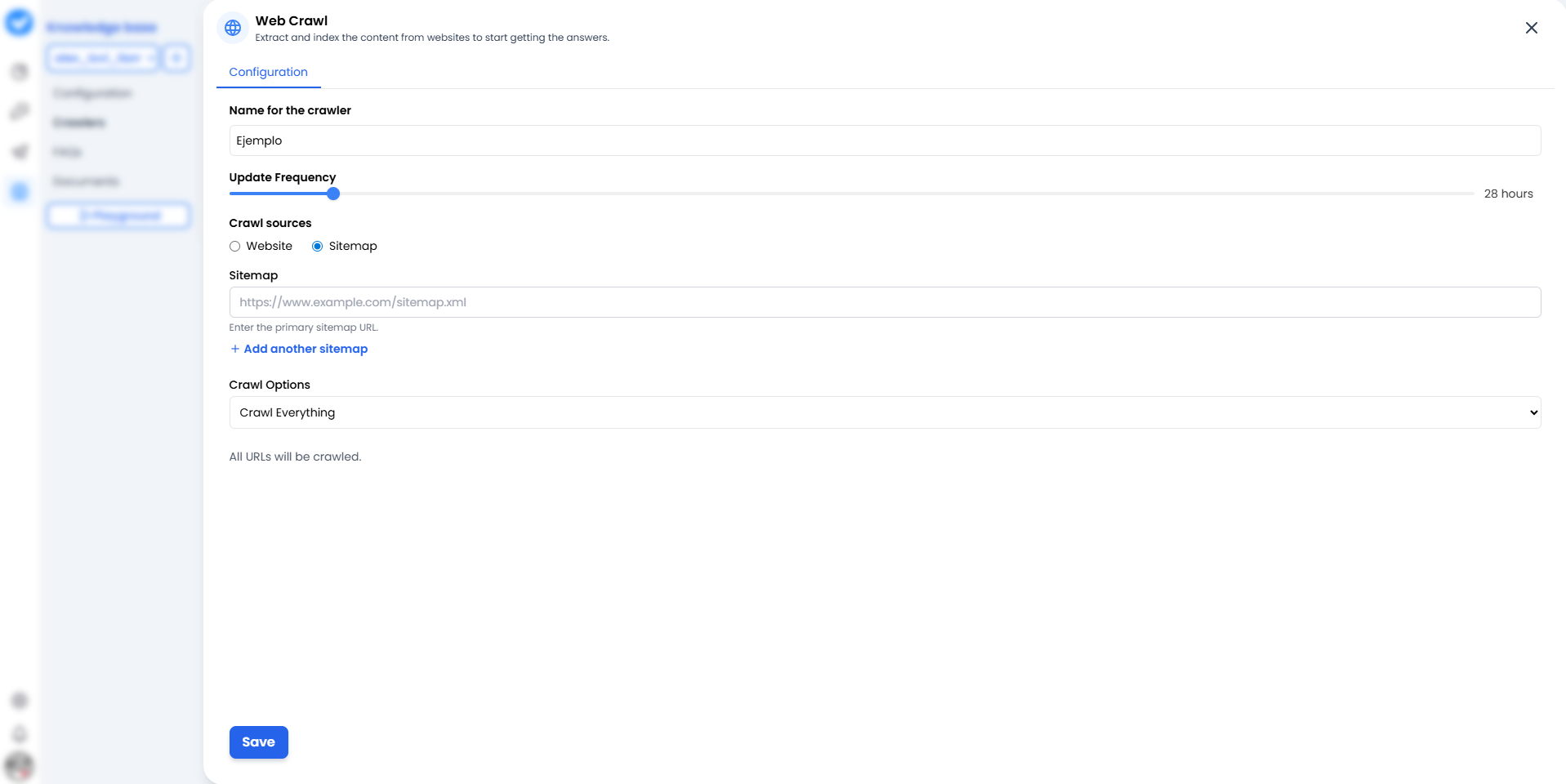
1. Nome per il crawler
Dagli un nome che identifichi chiaramente la fonte.- Sbagliato: “Test 1”.
- Giusto:
Supporto_Ufficiale_AiutooAggiornamenti_Blog_2024.
2. Frequenza di aggiornamento (Il ritmo)
Ogni quanto deve rileggere il sito web? Usa il cursore.- 24 ore: L’opzione standard. Controlla le modifiche una volta al giorno.
- Più frequente: Usa solo per notizie dell’ultima ora (consuma più risorse).
3. Fonti di crawling (La strategia)
Qui decidi come il bot entra in casa tua:- 🌐 Sito web: Il bot parte dalla homepage e segue i link uno per uno (come un umano curioso). Buono per scoprire contenuti.
- 🗺️ Sitemap (Nuova e migliorata!): Gli dai una mappa esatta (
sitemap.xml). La parte migliore? Non sei più limitato a una sola. Puoi cliccare + Aggiungi un’altra sitemap per fornire al bot più mappe contemporaneamente. Puoi anche usare il pulsante Controlla Sitemap per verificare che funzionino correttamente prima del lancio. Più veloce, più pulito e molto più efficiente.
4. Opzioni di crawling (L’ambito)
- Crawla tutto: Leggerà tutto quello che trova.
- Sotto-percorsi: Puoi limitarlo a
/blogo/prodotticosì non perde tempo sulla pagina “Chi siamo”.
⚠️ Importante: Assicurati che il tuo sito web non blocchi i bot (controlla il tuo robots.txt). Se chiudi la porta, non potrà imparare!
📄 Gestire la tua conoscenza (La scheda “Pagine”)
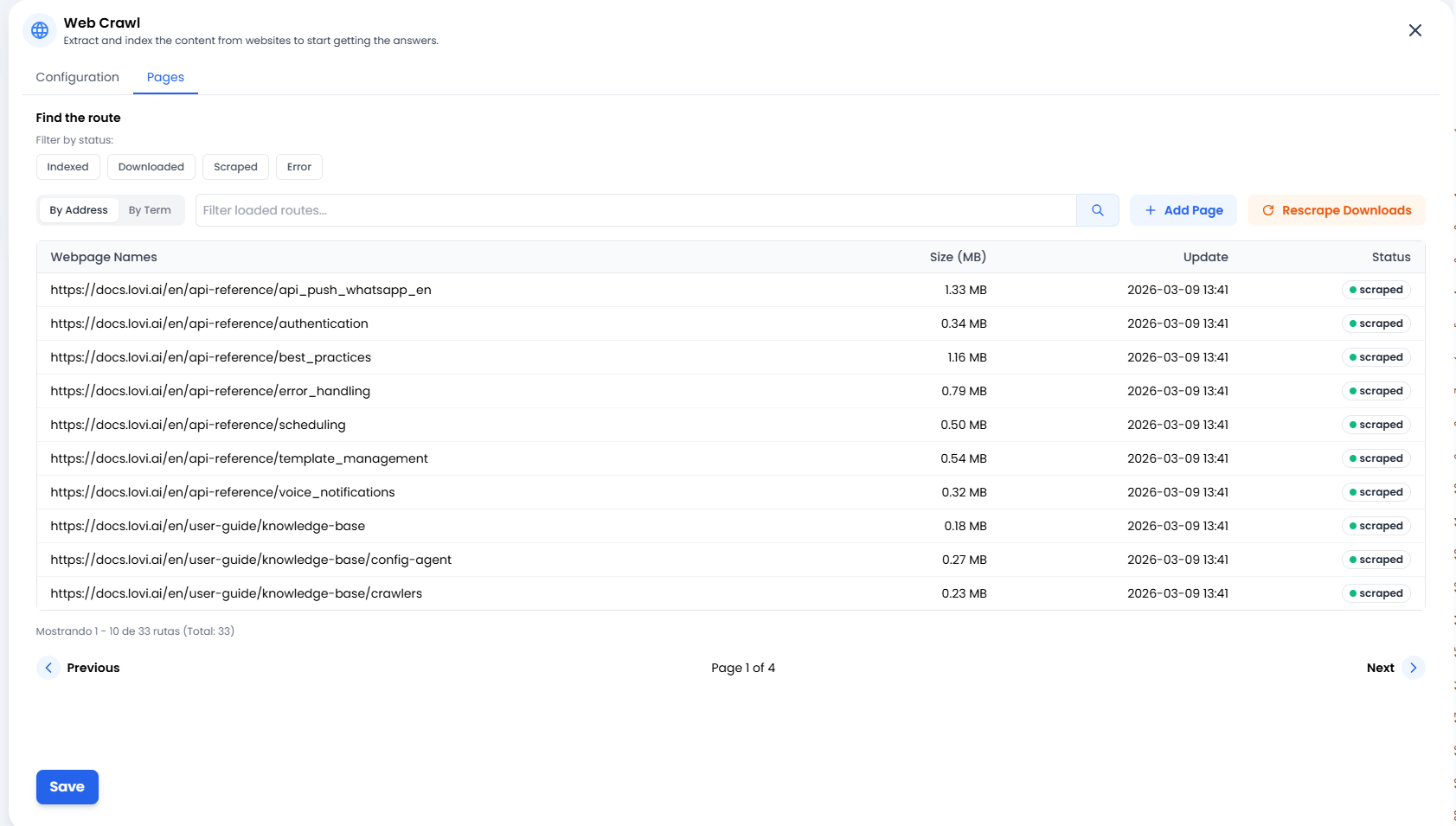
➕ Aggiungi pagina (Precisione chirurgica)
A volte non hai bisogno di crawlare un intero sito web o una sitemap completa. Se hai appena pubblicato un singolo nuovo articolo del blog o un articolo esterno che vuoi che il bot impari subito, clicca semplicemente + Aggiungi pagina. Questo ti permette di iniettare manualmente URL specifici direttamente nel cervello del bot.🔄 Riscraping dei download (La seconda possibilità)
Si è interrotta una connessione al sito web? O forse hai aggiornato il testo sul tuo sito web e vuoi che il bot lo impari immediatamente senza aspettare il prossimo ciclo programmato? Clicca il pulsante Riscraping dei download. Questo dice al sistema: “Prendi tutti i documenti che abbiamo già scaricato e prova a estrarre di nuovo le loro informazioni.” È il pulsante di aggiornamento perfetto.📊 Semafori di stato (Cosa sta succedendo?)
Nella lista delle Pagine, vedrai lo stato esatto di ogni singolo URL. Ecco cosa significano:- 🟢 Scraping/Indicizzato: Successo! ✅ Il contenuto è stato letto, elaborato ed è ora memorizzato in sicurezza nel cervello dell’agente.
- 🟠 Scaricato: La pagina è stata scaricata ma non ancora elaborata (sta ancora “digerendo” le informazioni).
- 🔴 Errore: Qualcosa è andato storto. Il sito web potrebbe essere offline, richiedere un login, o avere un firewall anti-bot che blocca il passaggio.
🎓 Riepilogo delle migliori pratiche (Cheat Sheet)
Per mantenere una libreria di conoscenza pulita e utile:- Le sitemap multiple sono le tue migliori amiche: Invece di crawlare un sito web enorme, fornisci sitemap specifiche (es.
sitemap-prodotti.xmlesitemap-blog.xml). Mantiene il bot focalizzato. - Evita le pagine inutili: Non hai bisogno di indicizzare “Carrello”, “Login” o “Note legali”.
- Nomi chiari: Quando hai 10 crawler, sarai contento di averli chiamati
FAQ_ITeFAQ_ENinvece diweb1eweb2. - Aggiunte chirurgiche: Usa il pulsante + Aggiungi pagina per aggiornamenti rapidi invece di forzare un crawl completo del tuo sito.
🆘 Risoluzione rapida dei problemi
| Problema | Probabile soluzione 🔧 |
|---|---|
| Lo stato dice “Errore” 🔴 | Il tuo sito web potrebbe bloccare i bot. Controlla le impostazioni del firewall. Se è stato un problema temporaneo, prova a premere Riscraping dei download. |
| Legge troppe pagine | Passa all’opzione Sitemap o restringi i Sotto-percorsi in modo che legga solo ciò che conta. |
| Le informazioni non si aggiornano | Controlla il cursore “Frequenza di aggiornamento”. Potrebbe essere impostato su “Mensile” quando hai bisogno di “Giornaliero”. |
| L’agente mescola i dati | Hai due crawler che leggono lo stesso contenuto? Rimuovi i duplicati. |