
🎯 ¿Para qué sirve esto?
- Mantenerlo actualizado: Si cambias un precio en tu sitio web, el crawler lo detectará en su próxima ejecución.
- Base de conocimiento enorme: Ideal si tienes cientos de artículos de ayuda o páginas de productos.
- Verificación: Permite al agente citar fuentes reales (“Según nuestro sitio web…”).
🛠️ Configurar un Crawler (Paso a Paso)
Cuando haces clic en + Añadir Crawler Web, verás la pantalla de configuración. Piénsala como el mapa de misión para tu crawler.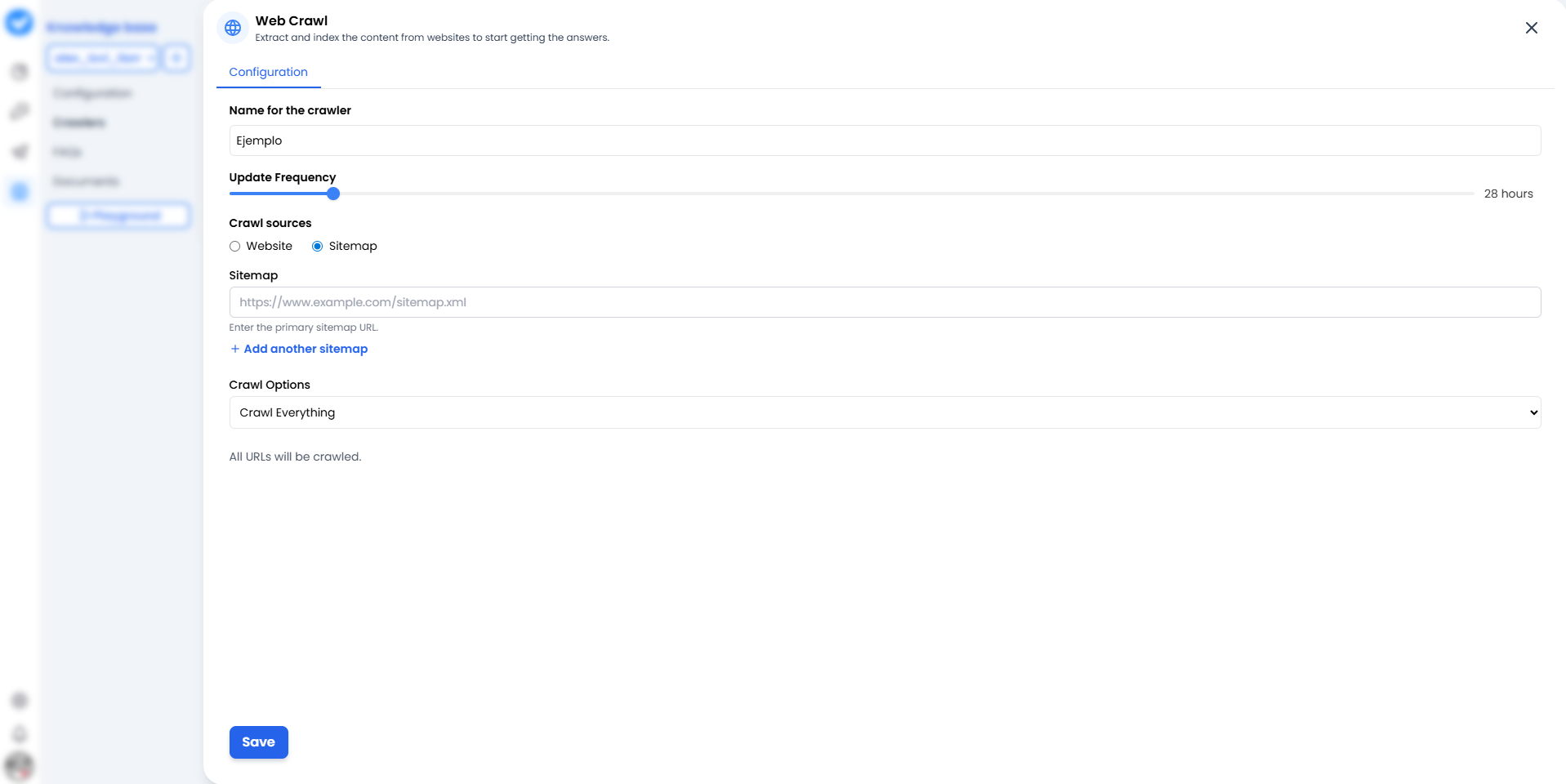
1. Nombre para el crawler
Dale un nombre que identifique claramente la fuente.- Malo: “Prueba 1”.
- Bueno:
Soporte_Oficial_AyudaoBlog_Actualizaciones_2024.
2. Frecuencia de actualización (El Ritmo)
¿Con qué frecuencia debe releer el sitio web? Usa el deslizador.- 24 horas: La opción estándar. Comprueba cambios una vez al día.
- Más frecuente: Úsalo solo para noticias de última hora (consume más recursos).
3. Fuentes de rastreo (La Estrategia)
Aquí decides cómo entra el bot en tu casa:- 🌐 Sitio web: El bot comienza desde la página principal y sigue los enlaces uno por uno (como un humano curioso). Bueno para descubrir contenido.
- 🗺️ Sitemaps (¡Nuevo y mejorado!): Le das un mapa exacto (
sitemap.xml). ¿La mejor parte? Ya no estás limitado a uno solo. Puedes hacer clic en + Añadir otro sitemap para alimentar al bot con múltiples mapas a la vez. También puedes usar el botón Comprobar Sitemaps para verificar que funcionan correctamente antes de lanzar. Más rápido, más limpio y mucho más eficiente.
4. Opciones de rastreo (El Alcance)
- Rastrear todo: Leerá todo lo que encuentre.
- Sub-rutas: Puedes restringirlo a
/blogo/productospara que no pierda tiempo en la página “Sobre nosotros”.
⚠️ Importante: Asegúrate de que tu sitio web no bloquee los bots (revisa tu robots.txt). ¡Si cierras la puerta, no podrá aprender!
📄 Gestionar tu Conocimiento (La Pestaña “Páginas”)
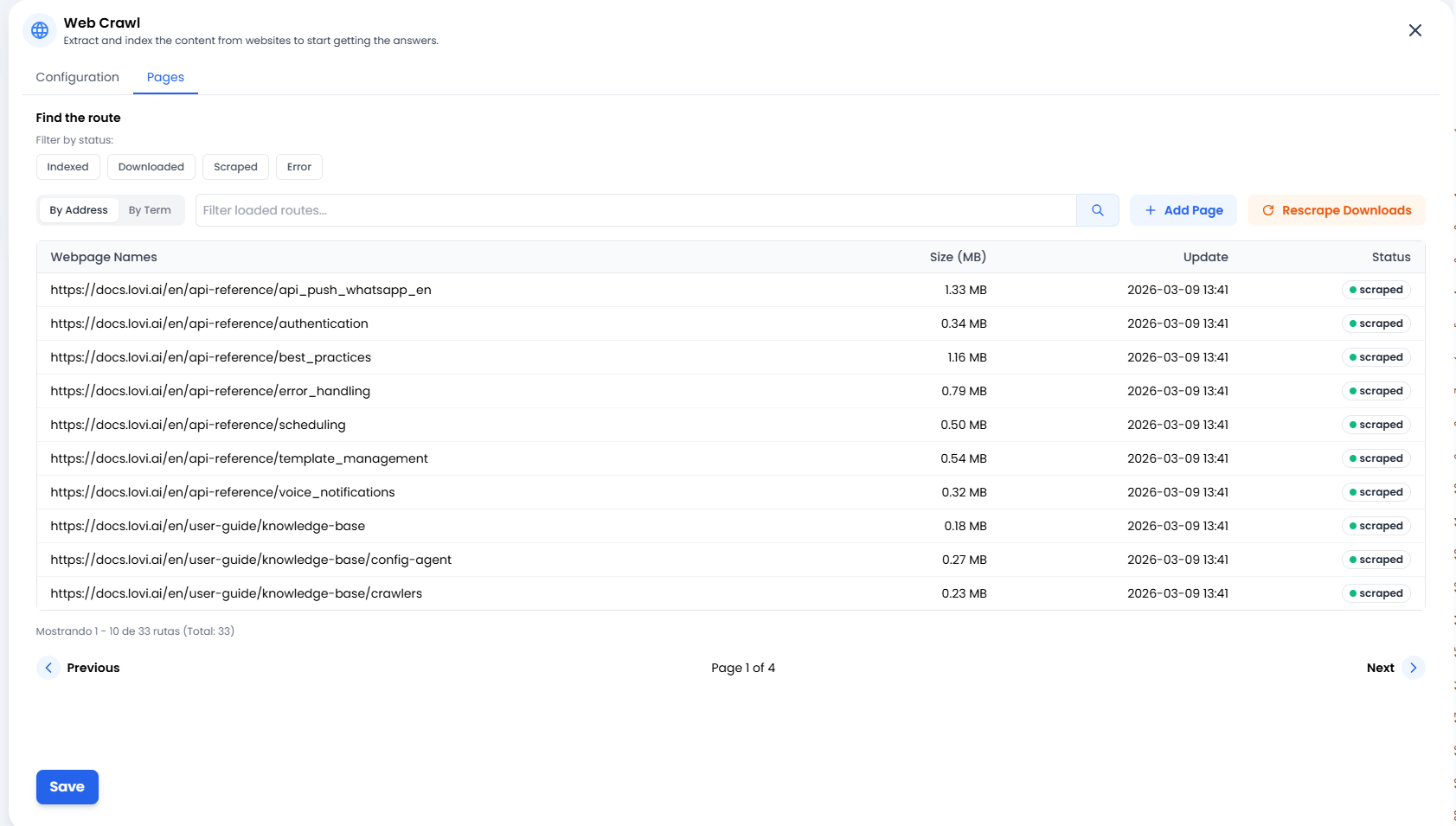
➕ Añadir Página (Precisión Quirúrgica)
A veces no necesitas rastrear todo un sitio web ni un sitemap completo. Si acabas de publicar una nueva entrada de blog o un artículo externo que quieres que el bot aprenda ahora mismo, simplemente haz clic en + Añadir Página. Esto te permite inyectar URLs específicas directamente en el cerebro del bot.🔄 Volver a Descargar (La Segunda Oportunidad)
¿Hubo un problema de conexión con un sitio web? ¿O quizás actualizaste el texto en tu sitio y quieres que el bot lo aprenda inmediatamente sin esperar al próximo ciclo programado? Haz clic en el botón Volver a Descargar. Esto le dice al sistema: “Toma todos los documentos que ya hemos descargado e intenta extraer su información de nuevo.” Es el botón de actualización perfecto.📊 Semáforo de Estado (¿Qué está pasando?)
En la lista de Páginas, verás el estado exacto de cada URL. Esto es lo que significan:- 🟢 Rastreado / Indexado: ¡Éxito! ✅ El contenido ha sido leído, procesado y ahora está almacenado de forma segura en el cerebro del agente.
- 🟠 Descargado: La página ha sido descargada pero aún no procesada (todavía está “digiriendo” la información).
- 🔴 Error: Algo salió mal. El sitio web puede estar caído, requerir inicio de sesión, o tener un firewall anti-bot bloqueando el acceso.
🎓 Resumen de Buenas Prácticas (Cheat Sheet)
Para mantener una biblioteca de conocimiento limpia y útil:- Los múltiples sitemaps son tu mejor amigo: En lugar de rastrear un sitio web enorme, proporciona sitemaps específicos (ej.
sitemap-productos.xmlysitemap-blog.xml). Mantiene al bot enfocado. - Evita páginas de relleno: No necesitas indexar “Carrito de Compras”, “Inicio de Sesión” ni “Aviso Legal”.
- Nombres claros: Cuando tengas 10 crawlers, te alegrarás de haberlos llamado
FAQ_ESyFAQ_ENen lugar deweb1yweb2. - Adiciones quirúrgicas: Usa el botón + Añadir Página para actualizaciones rápidas en lugar de forzar un rastreo completo de tu sitio.
🆘 Solución Rápida de Problemas
¡Todo listo! Con esto en su lugar, tu agente dejará de improvisar y empezará a responder con datos reales y actualizados de tus sitios web. 🕵️♂️📚